


Srikanth Sharma
March 27, 2026
5 Minutes read
Beyond JSON in IoT: Why Protocol Buffers Are Becoming the Preferred Message Format
In modern IoT ecosystems, devices generate massive volumes of telemetry data. Traditionally JSON has been the default format for IoT data transfer due to its simplicity and human readability. However, as IoT deployments scale to millions of devices and billions of messages, the inefficiencies of JSON become more visible.
Many modern IoT solutions architectures are now shifting toward schema‑based binary formats such as Apache Avro and Protocol Buffers (Protobuf) to improve performance, reduce bandwidth usage, and provide stronger data governance.
Typical JSON Message in IoT
{
“deviceId”: “sensor-1023”,
“timestamp”: “2026-03-10T12:30:15Z”,
“temperature”: 27.4,
“humidity”: 61.2
}
While simple, JSON messages contain repeated field names and text formatting that increase message size and processing overhead.
Why Schema-Based Messaging Matters
Schema-based serialization formats define the structure of data before transmission. This allows systems to encode messages in compact binary formats while ensuring consistent data structures across producers and consumers.
Example Protocol Buffer Schema
message SensorData {
string deviceId = 1;
int64 timestamp = 2;
float temperature = 3;
float humidity = 4;
}
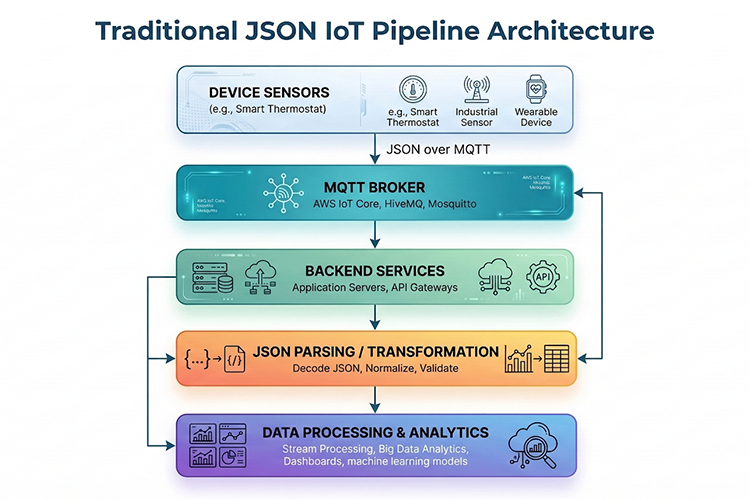
Architecture Diagram: Traditional JSON IoT Pipeline
This diagram represents a Traditional JSON IoT Pipeline Architecture, which is the most common industry standard for connecting smart devices to the cloud. It emphasizes a human-readable data flow that is easy to debug and highly compatible with most web services and application servers.
Core Components of the JSON Pipeline
- Edge Data Generation: Devices like smart thermostats and wearable sensors transmit data using the widely supported JSON format over the MQTT protocol.
- Scalable Brokerage: A central MQTT Broker (like AWS IoT Core or Mosquitto) manages the high volume of incoming messages, ensuring they reach the correct backend services.
- Transformation Layer: Because JSON is text-heavy, this architecture includes a dedicated Parsing & Transformation stage to decode, normalize, and validate the data before it hits the database.
- Downstream Value: Finally, the processed data is funneled into Big Data analytics and machine learning models to generate real-time dashboards and predictive insights.
While this approach is slightly less bandwidth-efficient than a binary (Protobuf) pipeline, its flexibility and ease of integration make it the go-to choice for most consumer and industrial IoT applications today.
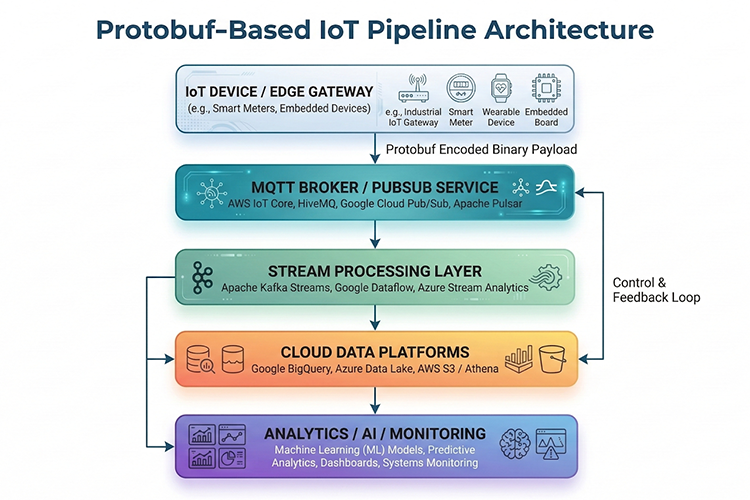
Architecture Diagram: Protobuf-Based IoT Pipeline
This diagram illustrates a high-performance Protobuf-Based IoT Pipeline, designed for environments where bandwidth efficiency and low-latency processing are critical. By utilizing Protocol Buffers (binary serialization) instead of traditional JSON, the architecture minimizes data overhead as information travels from edge devices to the cloud.
Key Stages of the Pipeline
- Edge Ingestion: IoT devices and gateways package telemetry into compact binary payloads.
- Message Brokerage: An MQTT or Pub/Sub service acts as the central nervous system, handling high-throughput message routing.
- Real-time Processing: A stream processing layer decodes the Protobuf data on the fly, performing normalization and validation.
- Storage & Intelligence: Data is stored in cloud-native platforms, feeding into AI models and monitoring dashboards for actionable insights.
The inclusion of a Control & Feedback Loop is particularly noteworthy, as it allows the analytics layer to send commands back to the edge devices, enabling a truly responsive, automated system.
Comparison of Message Formats
Based on the table comparing JSON, Apache Avro, and Protocol Buffers (Protobuf), here are a few key takeaways to help you decide which is best for your specific use case:
Efficiency vs. Accessibility
While JSON is the “universal language” of the web because it is human-readable and easy to debug, it carries a heavy performance tax. The text-based nature of JSON results in larger message sizes and slower parsing speeds compared to the binary alternatives.
The Power of "Binary" in IoT
Both Avro and Protobuf use binary encoding, which is why they are the preferred choices for high-performance pipelines.
- Protobuf is the winner for IoT and Microservices because it produces the most compact payloads, which is critical when dealing with low-power devices or expensive cellular data plans.
- Avro is a powerhouse for Big Data pipelines (like those using Apache Kafka) because it excels at handling complex data structures with its strong schema support.
Schema Strictness and Versioning
A major weakness of JSON is its “weak” version compatibility—if a field name changes or a data type shifts, downstream services often break.
- Protobuf and Avro enforce a Strong Schema. This means both the sender and receiver must agree on the data structure beforehand.
- This “contract” allows for Strong Version Compatibility, ensuring that as your IoT system evolves, older devices can still communicate with newer backend services without crashing the pipeline.
Speed is King
In a real-time analytics environment, Protobuf is “Very Fast” because it doesn’t have to scan through text to find values; it knows exactly where each piece of data sits in the binary stream. This reduces CPU overhead on both the tiny IoT sensor and the massive cloud processing engine.
| Feature | JSON | Apache Avro | Protocol Buffers |
| Encoding Type | Text | Binary | Binary |
| Message Size | Large | Compact | Very Compact |
| Schema Support | Optional | Strong Schema | Strong Schema |
| Parsing Speed | Slow | Fast | Very Fast |
| Human Readable | Yes | No | No |
| Version Compatibility | Weak | Strong | Strong |
| Typical Usage | APIs, Web apps | Data pipelines | Microservices, IoT messaging |
AWS IoT Reference Architecture
This AWS IoT Reference Architecture demonstrates how to build a scalable, serverless pipeline using Amazon’s managed services. It specifically highlights a hybrid approach—using MQTT for communication and Protobuf for payload efficiency.
Here are the key points of this architecture:
Unified Device Connectivity
- AWS IoT Core: Acts as the entry point for millions of devices. It handles the secure connection (TLS), authentication, and message brokerage without requiring you to manage servers.
- Protocol Efficiency: By using Protobuf, the architecture significantly reduces the bandwidth cost and power consumption of the devices compared to standard JSON.
The Intelligence: IoT Rules Engine
The Rules Engine is the “router” of the architecture. It evaluates incoming MQTT messages and, based on SQL-like statements, triggers specific AWS services. This allows for seamless data branching into four distinct paths:
- Real-time Streaming: Amazon Kinesis captures high-velocity data for immediate windowed analytics.
- Custom Logic: AWS Lambda performs on-the-fly data validation, enrichment, or external API calls.
- Long-term Storage: Amazon S3 serves as the “Data Lake,” storing raw binary payloads for future “cold” analysis or auditing.
- Time-Series Optimized: Amazon Timestream is ideal for sensor data where tracking changes over time is the primary goal, while DynamoDB provides low-latency lookups for state management.
Integrated Analytics & ML
By funnelling data through these specialized storage and processing layers, the architecture enables high-level business intelligence:
- Amazon SageMaker can pull from S3 to train ML models for predictive maintenance.
- Amazon QuickSight can connect to Timestream or DynamoDB to create real-time operational dashboards.

Conclusion
JSON remains useful for early IoT deployments, but large-scale systems benefit from binary serialization formats. Protocol Buffers and Avro significantly reduce message size, improve processing speed, and enforce schema governance.
By combining binary messaging formats with managed cloud messaging platforms such as AWS IoT services or Google Cloud Pub/Sub, organizations can build scalable, reliable, and cost-efficient IoT data pipelines.
Related Insights



Zero-Trust AI: Securing MCP-Based LLM Systems in Production
Siddharth Dange


Building Intelligent Agents on the Databricks Stack
Divyesh Patel