


Sushant Pramod Kuratkar
May 4, 2026
5 Minutes read
Engineering Scalable LLM Systems with RLM Principles
1. The Enterprise Problem: Where Simple LLM Usage Fails
Enterprise teams are no longer struggling to generate text with LLMs. Now, they struggle to control it. Large Language Models (LLMs) have improved document summarization, content generation, and text analysis. Still, most enterprise problems rarely fit into a single prompt. Engineers must build scalable LLM systems by moving beyond isolated prompt usage orchestrating LLMs in a structured way.
Real-world systems involve:
- Hundreds of requirements
- Cross-functional specifications
- Historical product versions
- Compliance documentation
- Structured metadata with traceability constraints
Trying to process such datasets in one LLM call introduces three key risks:
Context Saturation
Even large context windows are finite. Enterprise datasets can easily exceed them.
Semantic Drift
When too much information is passed at once, models may:
- Merge unrelated items
- Miss subtle distinctions
- Generate inconsistent outputs
Lack of Auditability
A single opaque LLM response limits traceability and weakens validation guarantees.
Engineering, compliance, and QA workflows demand more control than these limitations provide. We need an approach that scales reasoning while preserving control.
2. Understanding Recursive Language Model (RLM) Principles
A Recursive Language Model is not simply “an LLM used multiple times.” It is a design pattern based on staged reasoning.
The core idea is to break large reasoning tasks into smaller, structured units and let the model operate within controlled boundaries. This approach aligns closely with modern enterprise AI architecture, which distributes reasoning across controlled stages rather than centralized in a single prompt.
An RLM-inspired system typically includes:
- Problem decomposition
- Stage-wise reasoning
- Explicit state management
- Clear separation between model inference and execution logic
Instead of asking:
“Here are 200 requirements. Merge duplicates.”
We design a system that:
- Groups related items
- Processes them incrementally
- Maintains state externally
- Validates outputs at each stage
This shift design from prompt-centric to architecture-centric.
3. Architectural Building Blocks
To make this accessible beyond AI specialists, let’s break down the system into understandable components.
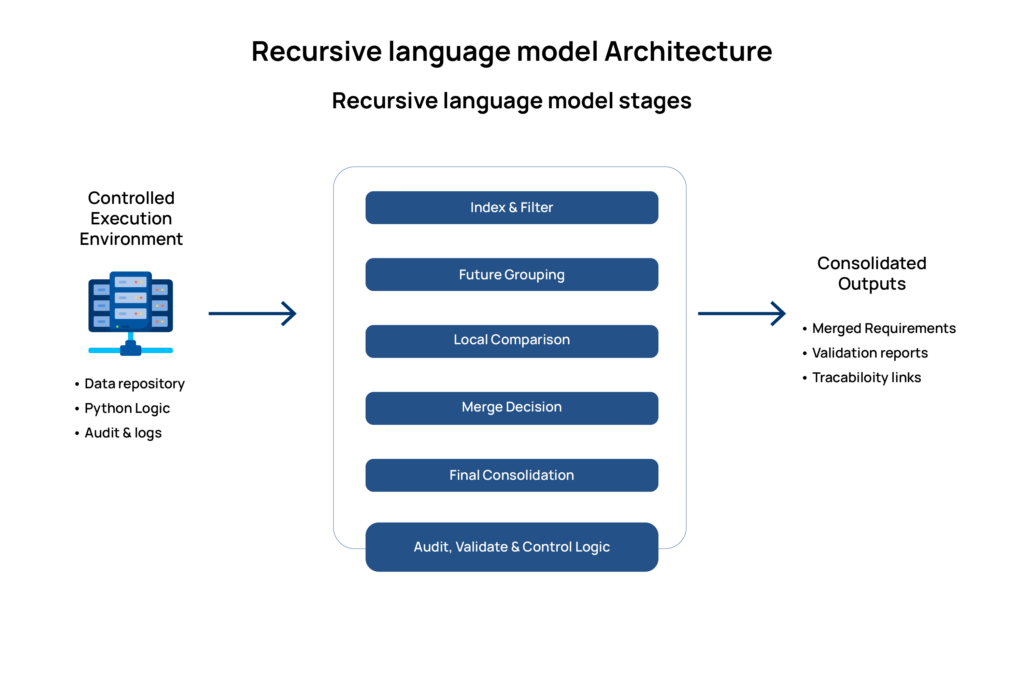
Structured Environment
All data lives in a controlled execution layer (e.g., Python services). The model never directly controls the full dataset.
Benefits:
- Clear state tracking
- Easier debugging
Deterministic workflow control
Staged Delegation
The system organizes the sequence of tasks:
- Indexing
- Grouping
- Local comparison
- Merge decision
- Final consolidation
The LLM handles semantic reasoning, not orchestration. Separating responsibilities is crucial for robust pipelines, reducing unpredictability while preserving language intelligence.
Hybrid (Neurosymbolic) Design
The architecture combines:
Neural layer:
- Understands semantics
- Detects overlap
- Generates merged text
Symbolic layer:
- Controls loops
- Enforces JSON schemas
- Validates IDs
- Maintains traceability
This hybrid design enables scalable systems without sacrificing clarity.

4. Concrete Example: Requirement Consolidation Pipeline
Consider a generic enterprise platform receiving the following requirements:
“Add multi-factor authentication for administrative users.”
“Enable account lockout after five failed login attempts.”
“Provide audit logging for all configuration changes.”
“Allow export of activity logs in CSV format.”
Instead of sending all requirements in one prompt for consolidation, we use a staged pipeline, a scalable pattern for LLM systems.
Lightweight Indexing
We first distill each requirement to its essential meaning. This minimizes token usage while preserving intent.

Feature Bucketing
The LLM groups semantically similar requirements:

Rules enforced:
- Each requirement appears once
- No duplication across buckets
Strict JSON validation
Incremental Merge Loop
A controlled loop processes one requirement at a time:

For each requirement:
- Identify candidates within the same bucket
- Request semantic merge decision
- Generate merged requirement text
- Record traceability links
The system executes the workflow. The model interprets the requirements.
5. Why This Architecture Matters
| Dimension | Single-Prompt Approach | RLM-Inspired Architecture |
| Scalability | Limited by context | Incremental |
| Traceability | Weak | Explicit |
| Error Isolation | Difficult | Stage-wise |
| Determinism | Low | Controlled |
| Maintainability | Hard to debug | Modular |
This structure is particularly valuable in:
- Product requirement management
- QA automation systems
- Compliance validation
- Regulated industry documentation
- Enterprise knowledge consolidation
6. Trade-offs and Engineering Realities
No architecture is universally optimal.
Latency
Multiple model calls increase total processing time.
Orchestration Overhead
Designing structured pipelines requires engineering effort.
Schema Enforcement
Strict JSON contracts require validation and fallback strategies.
However, the trade-off is worthwhile when:
- Accuracy matters more than speed
- Traceability is essential
- Outputs influence downstream automation
7. Extending the Pattern and Closing Perspective
This architectural pattern extends to many other enterprise scenarios, not only requirement consolidation.
Any domain involving large collections of structured text, semantic similarity detection, and deterministic output requirements can benefit from staged reasoning systems.
Typical applications include:
- Legal clause deduplication across contracts
- Cross-document compliance validation
- Multi-year audit log analysis
- Enterprise knowledge base consolidation
- Configuration or policy comparison across systems
In these environments, the challenge is not simply generating text. The real requirement is reasoning through large volumes of structured information while preserving traceability, consistency, and control.
Recursive Language Model (RLM) principles provide a practical framework for addressing this challenge. By decomposing complex reasoning tasks into smaller, verifiable steps, organizations can build systems that remain understandable and controllable even as data scale increases.
In practice, scalable LLM systems are most effective when implemented as structured reasoning pipelines where:
- Decomposition is intentional
- Execution remains controlled
- Outputs are validated at every stage
- System state is managed outside the model
This architectural approach is increasingly shaping how modern LLM orchestration systems are designed in enterprise environments.
At ACL Digital, these principles guide how LLM capabilities are integrated into production systems. Rather than relying on larger prompts or unchecked model autonomy, the focus is on structured orchestration around model reasoning. By combining semantic intelligence from LLMs with clear execution layers, it becomes possible to maintain audit-ready traceability, improve consistency across large datasets, and reduce the risk of inaccuracies through staged validation.
Conclusion
As enterprise adoption of generative AI accelerates, the success of LLM-based systems will depend less on model size and more on architectural discipline.
Treating language models as components within structured reasoning pipelines enables organizations to scale AI capabilities while maintaining reliability, traceability, and control.
The organizations that gain the most value from LLMs will not simply use them as standalone tools. They will design well-engineered systems around them.
If your organization is scaling LLM usage beyond prototypes, the challenge is no longer capability but control. Structured orchestration is where that transition begins.
References
The following resources informed the architectural ideas, implementation patterns, and conceptual framing discussed in this article.
Recursive Language Model Concepts
https://arxiv.org/abs/2210.03350
OpenAI Prompt Engineering and LLM Best Practices
https://platform.openai.com/docs/guides/prompt-engineering
LangChain Documentation
https://python.langchain.com/docs/
LlamaIndex Documentation
https://docs.llamaindex.ai/
Neurosymbolic AI Overview
https://www.ibm.com/topics/neuro-symbolic-ai
Design Patterns for LLM Applications
https://www.deeplearning.ai/short-courses/
Related Insights


Building Intelligent Agents on the Databricks Stack
Divyesh Patel



How Privilege Escalation Attacks Lead to Data Exfiltration
Gururaj Nagarakatte