


Vaishnavi Dolas
January 12, 2026
10 Minutes read
Building and Breaking ML/DL Pipelines: A Guide to Adversarial Testing with ART and Deepchecks
Machine Learning (ML) and Deep Learning (DL) now power some of the most mission-critical systems—fraud detection, healthcare diagnostics, autonomous services, and more. But while organizations invest heavily in improving model accuracy and performance, one crucial question often goes unanswered: How secure are these models against intentional manipulation?
In an era where attackers actively craft deceptive inputs to mislead AI systems, model security is no longer optional—it’s a strategic necessity. Understanding how your models respond under real-world threats can be the difference between trustworthy AI and costly vulnerabilities.
Why Adversarial Testing Matters
Real-world attacks have exposed how fragile models can be:
- Fraud systems bypassed by slightly modified inputs
- Medical models fooled by tiny pixel changes
- Autonomous systems misreading signs
- Facial recognition systems evaded with small triggers
High accuracy does not guarantee high reliability. Traditional validation assumes clean data—an unrealistic assumption when attackers actively exploit model weaknesses.
The Limitations of Traditional Testing
Cross-validation and accuracy checks measure performance—not robustness. A model never “stress-tested” against attacks is like a boxer who’s never faced a real opponent. In production, that opponent is an adversary crafting deceptive inputs.
Current Defenses and Their Gaps
- Adversarial Training improves robustness but is computationally expensive.
- Input Sanitization filters noisy data but adaptive attackers bypass it.
- Model Ensembles increase cost without solving root vulnerabilities.
- Certified Defenses offer guarantees but remain impractical for complex systems.
Our Experimental Approach: Comprehensive Security Testing
Our framework systematically evaluates vulnerabilities through adversarial testing—breaking models before attackers do. Using the Adversarial Robustness Toolbox (ART) and Deepchecks, we simulate training-time (poisoning) and inference-time (evasion) attacks, validate data integrity, and measure impact.
Key features: covers both ML and DL pipelines, provides measurable robustness metrics, compatible with Scikit-learn, PyTorch, and TensorFlow, and generates automated validation reports.
Adversarial Threat Landscape
Data Poisoning corrupts training data to insert hidden behaviors.
Model Evasion crafts inputs to fool trained models during inference. Both are dangerous—one corrupts learning, the other exploits perception.
The Security Toolkit
ART (The Offensive Red Team)
Provides a rich library of poisoning and evasion attacks, generating real adversarial examples to test live model responses.
Deepchecks (The Defensive Blue Team)
Validates datasets and models pre- and post-attack, detecting anomalies, quantifying degradation, and producing automated reports.
Key Evaluation Metrics
- Clean Accuracy – Model performance on clean data (baseline)
- Poisoned Accuracy – Performance after training on compromised data
- Attack Success Rate (ASR) – Percentage of successful adversarial manipulations
- ASR > 90% → severe vulnerability
- ASR < 50% → strong resistance
Case Study 1: ML Pipeline (Tabular Data)
Setup: A Support Vector Classifier (SVC) trained on the Breast Cancer Wisconsin dataset.
Attack: A Clean Label Backdoor inserts subtle numeric patterns without changing labels. About 12% of training samples were poisoned.
How We Implemented the Attack
We configured the Clean Label Backdoor attack in a simple config.yaml file using ART’s PoisoningAttackCleanLabelBackdoor class.
Key parameters included:
- max_iter / eps_step – control optimization duration and step size
- eps (Epsilon) – defines the maximum perturbation allowed. A smaller value (e.g., 0.3) keeps changes subtle and hard to detect
- norm = 2 – uses the L2 (Euclidean) distance to measure perturbation
- poison_percent = 12% percentage of training data to poison
- target_class = 1 instructs the model to misclassify benign samples as malignant
An automated script executed the poisoning and retrained the SVC model on the corrupted dataset.
Quantifying the Damage
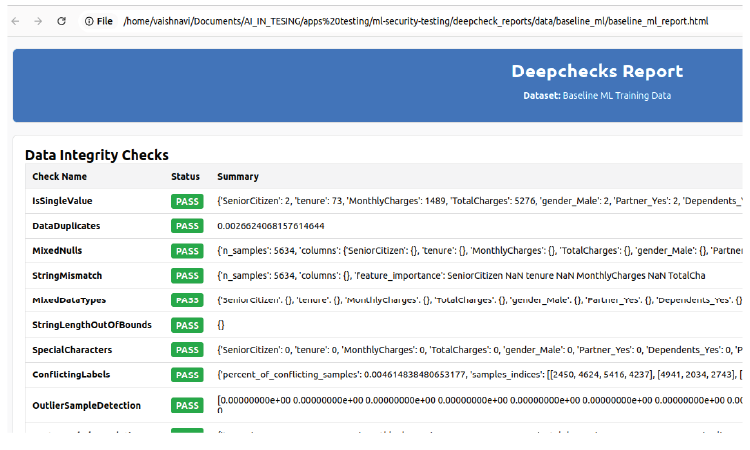
The poisoned model appeared normal but hid a serious flaw. Deepchecks analysis revealed:
- No conflicting labels confirming the attack’s stealth
- Statistical anomalies in the poisoned features, pinpointing where the trigger was injected
Results
- Deepchecks detected statistical anomalies but no label conflicts—showing the stealth of the attack
- When triggered inputs were applied, the model consistently misclassified them
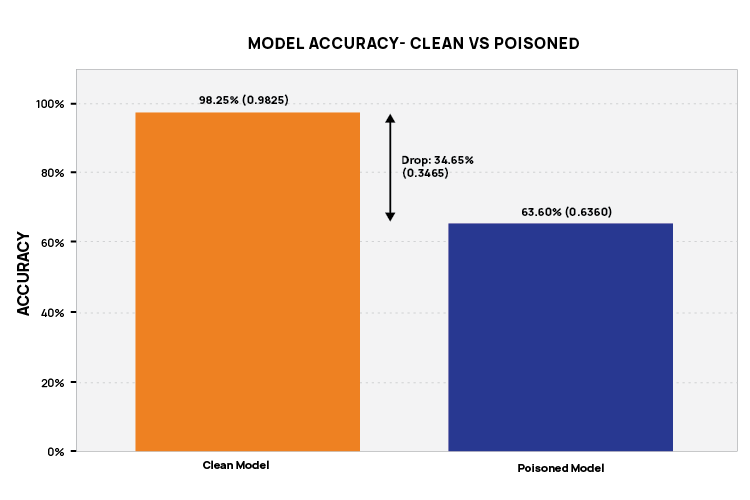
- The poisoned model’s accuracy dropped significantly, confirming compromised reliability
- Deepchecks detected statistical anomalies but no label conflicts—showing the stealth of the attack
- When triggered inputs were applied, the model consistently misclassified them
- The poisoned model’s accuracy dropped significantly, confirming compromised reliability
Model Performance Comparison
When tested with trigger samples, the compromised model consistently misclassified them, showing clear reliability loss. Key evaluation metrics included:
- Clean Model Accuracy: Baseline performance on unaltered data
- Poisoned Model Accuracy: Performance after training on corrupted data
- Performance Degradation: The accuracy drop between clean and poisoned models, revealing the extent of attack impact
Case Study 2: DL Pipeline (Image Data)
Setup: A CNN trained on the CIFAR-10 dataset (classes: deer, dogs, horses).
Attack: A Backdoor Poisoning Attack stamped a small 3×3 green square on 40% of training images and mislabeled them as “deer.”
Experimental Results



Results
- Clean model classified correctly; poisoned model misclassified all triggered images as “deer”
- Attack Success Rate exceeded 95%, proving a successful and powerful backdoor
- The trigger affected only 0.88% of image area, showing how small changes can have massive effects

The Verdict: From Accuracy to Trust
Our findings show that accuracy alone is not security. A model can perform well yet remain vulnerable to small, crafted manipulations. By combining ART’s offensive power with Deepchecks’ defensive validation, we can measure robustness, detect hidden weaknesses, and build trust in production AI systems.
Key production questions:
- Is the model resilient against manipulation?
- Is it reliable under hostile inputs?
- Is it trustworthy for critical decisions?
Best Practices for Securing ML/DL Models
1. Check your data before training
Make sure the data is clean, not changed by anyone, and doesn’t contain anything suspicious. Bad data → bad model.
2. Train the model to handle attacks
Use adversarial examples during training so the model learns to stay stable even when someone tries to fool it.
3. Use explainability tools
Regularly check why the model is making certain predictions. If it’s relying on something odd, that’s a red flag.
4. Protect the model’s API
Only allow authorized users, and limit how many requests they can make. This prevents model theft and misuse.
5. Monitor the model after deployment
Track incoming data and model outputs. If something suddenly changes, it may be an attack or data drift.
Conclusion: Hardening the AI Lifecycle with ACL Digital
As AI becomes foundational in healthcare, finance, and security, we must evolve from building models to hardening them. Frameworks like ART and Deepchecks bring “Red Team–Blue Team” adversarial testing into the ML lifecycle—just as DevSecOps reshaped software security.
At ACL Digital, we focus on building secure, transparent, and resilient AI systems that can withstand real-world threats. Our approach integrates robust model evaluation, adversarial defense, and continuous monitoring, ensuring that AI solutions not only perform but also protect.
The future of AI isn’t just about intelligence—it’s about resilience, trust, and responsible defense. With ACL Digital, we make sure AI remains safe, explainable, and ready for the challenges ahead.
Related Insights


Building Intelligent Agents on the Databricks Stack
Divyesh Patel



How Privilege Escalation Attacks Lead to Data Exfiltration
Gururaj Nagarakatte