


Bhargav Reddy
April 3, 2026
5 Minutes read
Context Is Everything: Choosing Between RAG and Fine-Tuning for NLU2SQL
In enterprise analytics environments, generating accurate SQL from natural language is not just a convenience—it is a reliability requirement. Even minor errors in joins, filters, or logic can lead to misleading insights and costly decisions.
As organizations adopt NLU2SQL systems to democratize data access, the challenge shifts from selecting powerful models to designing architectures that provide reliable business context. This blog explores how Query Mapping RAG and fine-tuning approaches address this challenge, helping teams build production-ready NLU2SQL systems that deliver consistent, auditable, and accurate results.
The Brittleness of 'Almost Correct' SQL
The Hook
In the world of enterprise analytics, a SQL query that is “90% correct” is 100% useless. A single missing join or a misplaced WHERE clause doesn’t just return an error — it returns wrong data that can drive multi-million-dollar business missteps. Silent, confident errors are the most dangerous failure mode in production analytics systems.
The Problem
While state-of-the-art models like Claude 3.5 / 4.5 Sonnet possess exceptional general-purpose reasoning, they lack the specific “business context” of your internal database — the domain jargon, the implicit filters (e.g., is_archived = 0), and the complex multi-hop relationship paths that only exist in your organisation’s data model.
The Solution Path
Recognising that a pure ‘black box’ approach was insufficient, we evolved from naïve schema retrieval towards a tightly governed Query Mapping RAG architecture — trading raw model creativity for deterministic, auditable SQL generation grounded in verified business logic.
Key Insight
Production-grade Text-to-SQL is fundamentally an architecture problem, not merely a model-selection problem. The best model in the world still needs the right contextual scaffolding to be reliable.
The Limitations of 'Schema-Only' Hybrid RAG
Where Most Teams Start
The natural first step for any team building NLU2SQL is Hybrid RAG: retrieve the relevant table schemas (DDLs) and column descriptions, inject them into the prompt, and let the LLM reason from raw ingredients. For simple databases with a handful of well-named tables, this works surprisingly well.
Why It Failed in Production
As schema complexity grew, three failure modes emerged at scale:
- Inconsistency: Even when the correct schema was retrieved, the model would occasionally join tables through the wrong foreign-key path, producing structurally valid but semantically incorrect SQL.
- Logic Ambiguity: Natural language is inherently vague. ‘Active Consultants’ might mean is_active = 1, contract_status = ‘current’, or a combination of three filters — and the LLM had no way to distinguish between them without explicit guidance.
- Hallucination: When retrieved context was noisy or incomplete, models would occasionally invent column names or reference tables that did not exist, producing queries that failed silently or errored unpredictably.
Key Insight
Production-grade Text-to-SQL is fundamentally an architecture problem, not merely a model-selection problem. The best model in the world still needs the right contextual scaffolding to be reliable.
Technical Deep Dive: The Agentic Workflow
Orchestration with LangGraph
The NLU2SQL pipeline is orchestrated as a multi-node LangGraph state machine, enabling fine-grained control over each stage of query processing, including safety gates, self-correction loops, and access control enforcement.
- Input Validation (validate_input): The entry node ensures incoming queries are syntactically sound, semantically coherent, and within the defined scope of the system.
- Memory Injection (inject_memory): Relevant context from prior conversation turns is injected at this stage, enabling multi-turn dialogue and follow-up query refinement without re-stating the full context each time.
- Classify & Rewrite (classify_and_rewrite_query): User intent is classified before SQL generation begins. This node distinguishes between database queries, graph traversals, report generation, and general conversational requests.
- NLU2SQL Node (nlu2sql): The core generation engine. Guided by retrieved Golden Mappings and the injected schema context, Claude 4.5 Sonnet generates production SQL against the target database dialect.
- Reflection & RBAC (reflection_node + rbac_check): A confidence-gated self-correction loop re-evaluates generated SQL when confidence falls below 75%. RBAC checks then ensure the generated query only accesses tables and columns the requesting user is authorised to view.
- Response Generation (response_generation): The final node assembles the user-facing response, optionally executing the validated SQL, formatting results, and appending a feedback capture mechanism to improve the Golden Store over time.

Figure 1: The LangGraph state machine — input validation, memory injection, and a confidence-gated reflection loop minimise hallucinations and enforce access control.
The Pivot: Moving to Query Mapping RAG — The 'Golden Store'
The Strategy
Instead of asking the model to build every query from scratch using raw ingredients (DDLs), we provide it with “verified recipes” — curated, business-validated NLQ-to-SQL mappings that encode not just the correct SQL, but the correct business intent behind each class of query.
Implementation Details
- The Golden Dataset: A curated, JSON-based store of Natural Language Question (NLQ) to Production SQL mappings, reviewed and approved by domain experts. Each entry includes the original question, the canonical SQL, and relevant metadata tags.
- Semantic Matching: Using Amazon Titan embeddings and a Qdrant vector store, the system identifies the k most semantically similar verified queries to any incoming user request — prioritising intent alignment over surface-level keyword matching.
- Dynamic Grounding: The retrieved ‘Golden Examples’ are injected into the system prompt as few-shot demonstrations, steering Claude 4.5 Sonnet to follow established business logic, correct join paths, and organisation-specific SQL dialects.

Figure 2: Query Mapping RAG flow — semantic retrieval via Amazon Titan grounds Claude 4.5 Sonnet in verified business logic rather than raw database schemas.
RAG vs. Fine-Tuning: A Strategic Decision Matrix
The choice between Query Mapping RAG and Fine-Tuning is not binary — it is architectural. The table below provides a comparative framework for decision-makers evaluating both approaches against the demands of a production NLU2SQL system.
| Feature | Query Mapping (RAG) | Fine-Tuning |
| Adaptability | ✓ Instant — update the vector index only. | ⚠ Slow — weeks of data prep and retraining. |
| Consistency | ✓ High for known patterns. | ✓ High for stable, repetitive query families. |
| Schema Changes | ✓ Handled via metadata updates. | ⚠ Requires full retraining for new columns/tables. |
| Traceability | ✓ Clear — Golden Query is visible and auditable. | ⚠ Opaque — logic is baked into model weights. |
| Novel Queries | ⚠ Degrades without a close match in the store. | ✓ Better generalisation after domain training. |
| Data Required | Curated NLQ-SQL pairs for the Golden Store. | Large labelled fine-tuning dataset. |
| Cost & Latency | ⚠ Minimal inference overhead, low upfront cost. | Higher upfront cost; faster at inference time. |
| Recommended Use | Primary architecture — resolves 80% of queries. | Surgical fix for long-tail novel queries (20%). |
Table 1: Strategic comparison of Query Mapping RAG and Fine-Tuning across key production dimensions. Green (✓) indicates an advantage; amber (⚠) indicates a caveat or constraint.
Key Insight
Production-grade Text-to-SQL is fundamentally an architecture problem, not merely a model-selection problem. The best model in the world still needs the right contextual scaffolding to be reliable.
The Next Frontier: Can Fine-Tuning Stabilise the 'Long Tail'?
The Non-Query Challenge
For questions that lack a sufficiently close match in the Golden Store, the system falls back on the model’s raw generalisation capability. This is where quality degrades most visibly — not because the model is incapable, but because it has no verified anchor for unfamiliar patterns.
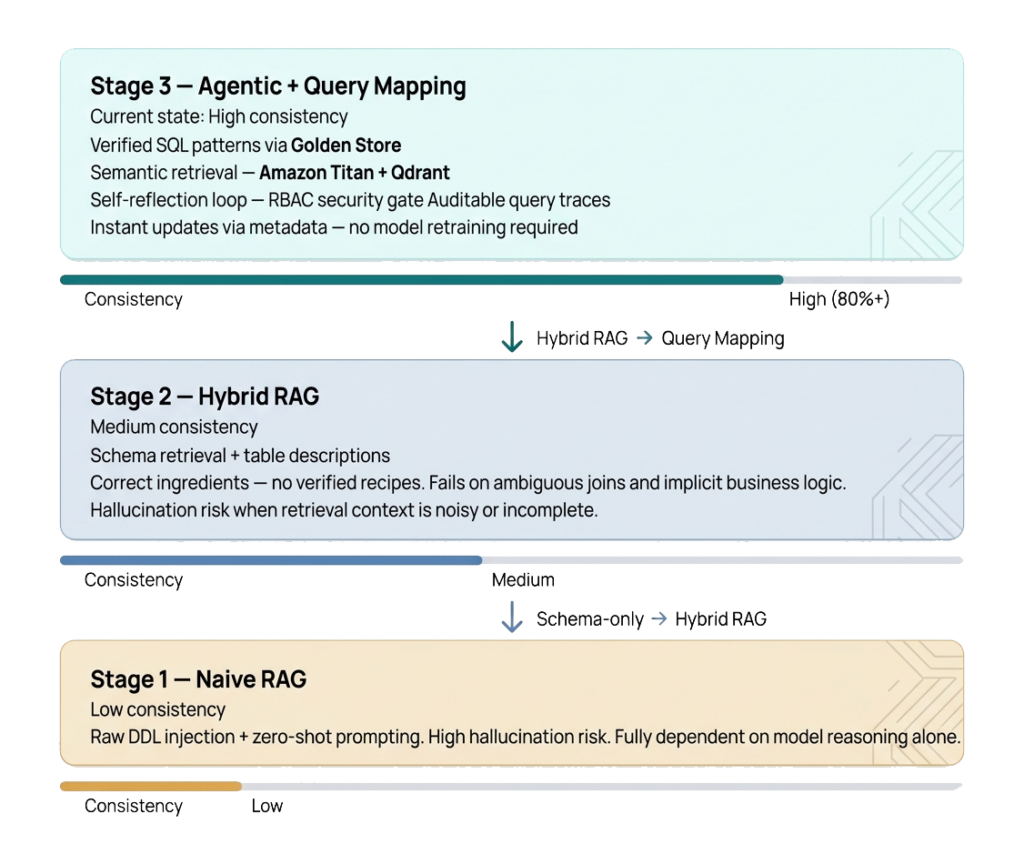
Figure 3: NLU2SQL architectural maturity model — the progression from raw DDL injection to intent-based Query Mapping yields compounding consistency gains at each stage.
The Fine-Tuning Hypothesis
A critical distinction guides our approach: RAG is best for ‘facts’ (what tables exist, what columns mean, which joins are correct), while Fine-Tuning is best for ‘behaviour’ (how the model structures queries, how it handles ambiguity, how consistent its output style is).
The Research Goal
We are investigating whether light fine-tuning on stable, high-frequency query families can meaningfully increase the base consistency of the model when it encounters novel, unmapped questions.
- Target: Stable query families with 50+ verified examples in the Golden Store.
- Method: Supervised fine-tuning on NLQ-SQL pairs from the Golden Dataset, with held-out evaluation on adversarial and novel questions.
- Success Metric: Reduction in reflection loop retry rate for out-of-distribution queries, without degradation on in-distribution performance.
Why AWS Bedrock and Claude 4.5 Sonnet?
Enterprise-Grade Infrastructure
- High Availability & Scalability: AWS Bedrock provides managed, auto-scaling inference with enterprise SLAs — eliminating the operational overhead of self-hosting model endpoints.
- Low-Latency Inference: Bedrock’s regional endpoints ensure that our LangGraph nodes complete within the latency budgets required for interactive analytics dashboards.
- Security & Compliance: Native IAM integration, VPC endpoints, and AWS PrivateLink ensure that sensitive query data never traverses the public internet.
Why Claude 4.5 Sonnet Specifically
- Out-of-the-Box SQL Capability: Claude’s exceptional zero-shot SQL reasoning means that even novel queries receive structurally sound outputs — reducing the blast radius when the Golden Store produces no close match.
- Instruction Following: Claude’s strong adherence to complex, multi-constraint system prompts makes it an ideal partner for a RAG-led architecture — it reliably follows few-shot examples without drifting towards its prior.
- Context Window: The 200K token context window accommodates large schemas, extensive few-shot examples, and multi-turn conversation history simultaneously — a prerequisite for production NLU2SQL.
Conclusion: Architecture Beats Model Choice
The central lesson from building production NLU2SQL systems is deceptively simple: the quality of the architecture matters more than the choice of model. A mediocre prompt with a brilliant model will consistently underperform a well-engineered RAG pipeline with a capable-but-not-cutting-edge model.
The Query Mapping RAG architecture described in this post addresses the core failure modes of schema-only approaches — inconsistency, ambiguity, and hallucination — by grounding generation in verified business logic rather than asking the model to infer it from raw structure.
Fine-tuning is not a competitor to this approach; it is its natural complement. Once the RAG architecture has stabilised the 80% of queries that map cleanly to the Golden Store, fine-tuning can be applied with surgical precision to the remaining 20% — not to replace the RAG pipeline, but to elevate the model’s baseline behaviour when that pipeline produces no close match.
Final Verdict
Build for the architecture first. Start with Query Mapping RAG to solve the consistency problem. Measure your long-tail failure rate. Then — and only then — invest in fine-tuning to address what RAG cannot. Production reliability is earned incrementally, not granted by model selection.
Related Insights


Building Intelligent Agents on the Databricks Stack
Divyesh Patel



How Privilege Escalation Attacks Lead to Data Exfiltration
Gururaj Nagarakatte