Home / Blogs / The Validation Loop: Building Self-Healing Agents for Migration Pipelines
Manas Shenge
April 13, 2026
5 Minutes read
The Validation Loop: Building Self-Healing Agents for Migration Pipelines
The Problem with Automated Code Migration
Modern enterprises often rely on legacy database systems containing years of business logic written in procedural languages like PL/SQL. When organizations migrate to newer platforms or architectures, this logic must also be migrated. Consider the example of converting Oracle PL/SQL migration scripts into Python code running on InterSystems IRIS—a common requirement in AI-driven Database Migration and Legacy Modernization services within the Information Technology and Enterprise Software industry.
Large Language Models (LLMs) are highly capable of generating code translations. However, code generation alone is not sufficient. Generated scripts frequently fail due to syntax issues, runtime errors, missing dependencies, or subtle logic differences. Manually debugging these issues across hundreds or thousands of migration scripts becomes extremely time-consuming and inefficient, posing a major challenge in Generative AI and Intelligent Automation solutions for Data Engineering and Digital Transformation.
To solve this problem, we designed a system called the Validation Agent. Instead of trusting generated code blindly, the system automatically executes, diagnoses, and corrects errors before human review, bringing reliability to Enterprise AI and AI-powered Software Engineering services.
The Core Idea: A Self Correcting Migration Pipeline
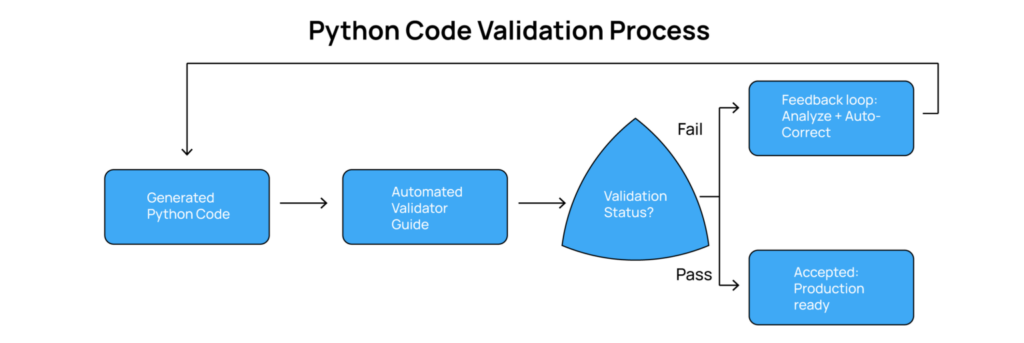
The Validation Agent introduces a feedback mechanism into the migration pipeline. Generated code is treated as unverified output and must pass through automated validation before being accepted, an approach that strengthens AI-driven Application Modernization and Automation frameworks.
System Architecture
The architecture uses intelligent multiple agents to ensure reliability and scalability, making it highly effective for Enterprise Software, BFSI, and Healthcare Technology industries, where accuracy is critical. Each component performs a specialized role in the migration pipeline.
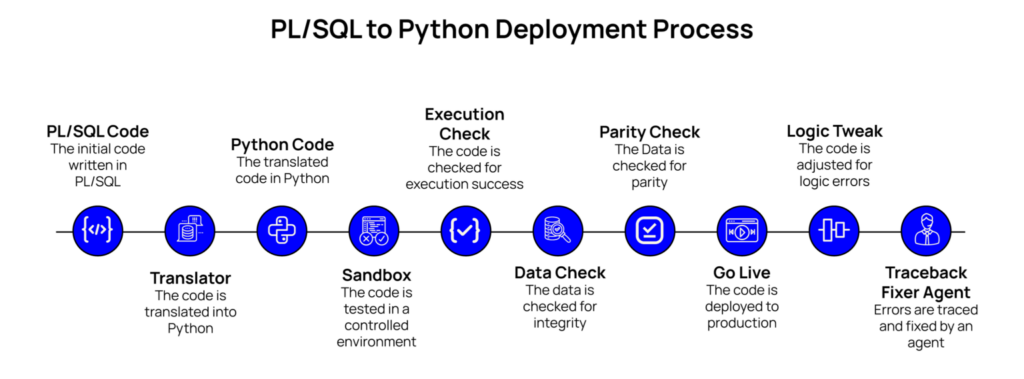
Architecture Flow:
The Dry Run Environment
One of the most important design decisions was to never execute generated migration scripts directly on production databases. Instead, we created a sandboxed IRIS environment with representative test data, an essential best practice in Data Engineering and AI-driven Software Testing services.
The Validator Agent is responsible for executing the generated Python script. It monitors runtime execution and captures any Python traceback errors in real time, leveraging capabilities widely used in AI-powered Debugging and Intelligent Automation services.
If the script runs successfully, the system proceeds to dataset validation. If the script fails, the captured traceback becomes the debugging signal used by the correction stage.
Traceback Analysis and the Corrector Agent
When a script fails, the system sends three inputs to the Corrector Agent:
The legacy Oracle script and the generated Python script are executed on the same dataset. The resulting tables are compared row by row to ensure data integrity, especially important in Healthcare Technology and Financial Systems.
Performance Benchmarking
Execution time and resource usage are measured to compare performance between the original PL/SQL and the Python implementation, ensuring efficiency in Enterprise Software and Data Engineering environments.
Lessons Learned
Key insights from building the validation loop:
Generated code should always be validated in a sandbox environment.
Python tracebacks provide structured debugging signals.
Automated correction works well for many runtime errors.
Human review is still necessary for complex edge cases.
Human in the Loop
While the system automates most debugging tasks, some migration scenarios still require human expertise. Complex procedural logic, dynamic SQL generation, and undocumented legacy behavior often require review by senior architects.
Conclusion
The Validation Loop transforms a simple code‑generation pipeline into a self‑healing migration system. By combining automated execution, traceback analysis, correction agents, and dataset validation, the system dramatically reduces manual debugging effort.
As AI‑driven software systems continue to evolve, pipelines capable of verifying and correcting their own outputs will become increasingly important.
What's Next
AI will start explaining its fixes – like “I changed this line because IRIS works this way.”Every change gets recorded for audits.At ACL Digital, we make AI that learns from mistakes.