

Vaishnavi Dolas
April 8, 2026
5 Minutes read
Is Your RAG System Ready for Production?
RAG applications are increasingly being adopted to power enterprise knowledge systems, enabling accurate information retrieval, contextual responses, and intelligent automation. In early testing, these systems often demonstrate strong performance, retrieving relevant data and generating confident answers. However, once deployed, challenges begin to emerge.
A user notices the system citing information that was never present in any document. A healthcare professional receives an incorrect clinical response presented as a verified fact. A finance user gets a fabricated policy number delivered with complete confidence. This is not bad luck – it is what happens when a RAG system is deployed without proper evaluation.
RAG (Retrieval-Augmented Generation) systems are now central to enterprise use cases such as internal assistants, customer support bots, compliance tools, and document intelligence. The idea is simple: providing a language model with access to enterprise data so it can generate answers grounded in that knowledge base. However, “it works in the demo” is not the same as “it is safe for production.” These systems can fail in subtle ways that remain invisible without structured evaluation. Without proper measurement, a system may appear reliable while quietly producing incorrect or unsupported answers.
This is why systematic evaluation is critical before deploying any RAG system at scale. To better understand how RAG compares with alternative approaches like fine-tuning in real-world architectures, read our blog on RAG vs Fine-Tuning for NLU2SQL architectures.
How RAG Systems Fail and Why It’s Hard to Detect
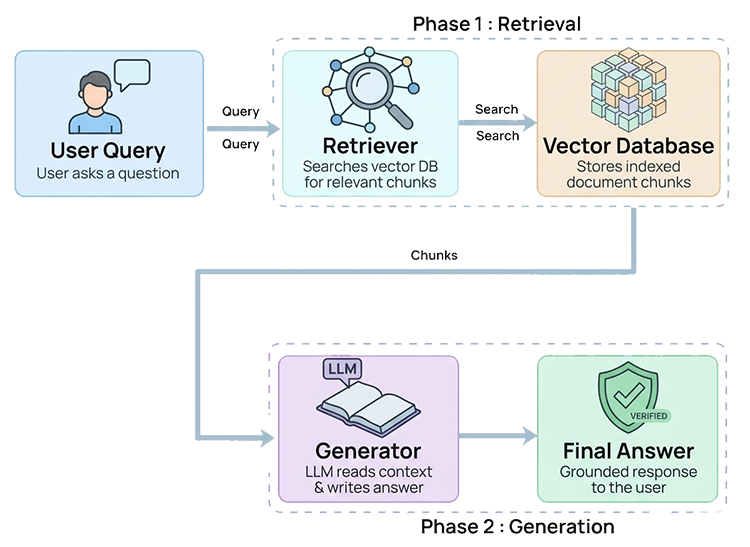
A RAG system operates through two core components:
- Retriever: Searches a vector database and retrieves relevant document chunks
- Generator: The language model that produces the final response using that context
Both components can fail. The challenge is that these failures often appear identical: a fluent, well-structured, and confident answer.
Retriever Failures
Failures in the retrieval stage typically include:
- Returning chunks that appear relevant but lack sufficient information to answer the query
- Missing critical information that exists within the knowledge base
- Returning too many loosely related chunks, introducing noise into the context
Generator Failures
Failures in the generation stage include:
- Ignoring retrieved context and relying on pre-trained knowledge
- Mixing factual context with fabricated claims
- Producing responses that are fluent but misaligned with the user’s query
The most dangerous failure mode is hallucination when the model generates statements that are not present in any retrieved document. For end users, there is often no clear signal that the response is incorrect. In regulated industries such as healthcare, banking, and legal services, this can introduce significant operational and compliance risk.
To understand how AI systems deliver real-time insights in dynamic environments, read our blog on edge computing for real-time intelligence.
Retrieval and generation failures are fundamentally different problems. A system may retrieve the correct documents but still generate hallucinated responses. In other cases, the generator may be reliable, but the retriever fails to provide the necessary context. Without structured evaluation frameworks, identifying the root cause is extremely difficult. In practice, you cannot fix what you cannot measure.
Key Metrics for Evaluating RAG System Performance
Evaluating a RAG system is not about running a few queries and checking whether answers “look right”. Reliable evaluation requires measuring multiple dimensions of system quality, each aligned to a specific stage of the pipeline. Similar approaches are used in optimizing AI models across edge environments.
Four core metrics are commonly used:
| Metric | What It Measures | Why It Matters |
| Faithfulness | Whether claims in the response are supported by retrieved context | Detects hallucinations |
| Answer Relevancy | Whether the response answers the user’s query | Detects intent drift |
| Context Precision | How many retrieved chunks are useful | Reduces noise |
| Context Recall | Whether all necessary information was retrieved | Identifies missing evidence |
Each metric corresponds to a specific failure mode within the RAG pipeline:
- Faithfulness: Detects hallucinations
- Answer relevancy: Identifies responses that miss the user’s intent
- Context precision: Reveals excessive irrelevant retrieval
- Context recall: Highlights missing information
Together, these metrics provide a diagnostic view of the system’s behavior.
How to Run a Structured RAG Evaluation
A reliable evaluation requires more than testing a few sample queries —it demands a structured and repeatable approach.
A typical RAG evaluation setup includes:
- A dataset of test questions reflecting realistic user queries
- Ground-truth answers that are verified as correct
- The system’s generated responses
- The retrieved document chunks used to generate each response
Capturing these elements enables evaluation of both retrieval and generation performance.
How Evaluation Tools Support RAG Assessment
Several open-source frameworks help automate and standardize the evaluation of RAG systems, enabling teams to measure performance consistently across both retrieval and generation stages.
- RAGAS Framework: Provides reference-free evaluation using LLMs to score RAG system components.

- DeepEval Framework: Offers a complementary RAG evaluation with similar core metrics but different implementation approaches.

- LangSmith Framework: Provides broader evaluation insights with additional metrics and terminology.
Key Evaluation Metrics Across RAG Frameworks
| Metric | What It Measures | Used In |
| Context Precision | Measures relevance of retrieved chunks and reduces noise | RAGAS, DeepEval |
| Context Recall | Evaluates completeness of retrieved information | RAGAS, DeepEval |
| Answer Relevancy | Assesses alignment of response with user query | RAGAS, DeepEval |
| Faithfulness | Ensures responses are grounded in retrieved context | RAGAS, DeepEval |
| Correctness | Evaluates overall accuracy of the generated response | LangSmith |
| Retrieval Relevance | Assesses quality of retrieved documents | LangSmith |
| Relevance | Measures alignment of final response with query | LangSmith |
| Groundedness | Ensures responses are based on retrieved data, not model assumptions | LangSmith |
Example Evaluation Workflow
A typical evaluation workflow includes:
- Prepare a dataset of representative user queries
- Define ground-truth answers
- Run questions through the RAG system and capture:
- Generated response
- Retrieved document chunks
- Score responses using evaluation frameworks
- Analyze metrics to identify weaknesses and failure patterns
This process shifts testing from subjective judgment to measurable evaluation.
Insights from RAG Evaluation
Structured evaluation often uncovers issues that remain invisible during manual testing.A system may appear reliable during development but reveal patterns such as:
- Responses containing unsupported claims
- Retrievers returning loosely related documents
- Generators ignoring retrieved context
Analyzing metrics collectively also helps diagnose root causes. For example:
- High retrieval quality but low faithfulness indicates generation issues
- Poor context recall suggests document chunking or indexing problems
Evaluation transforms hidden system behavior into measurable and actionable insights.
Defining Production Readiness for RAG Systems
Production readiness is determined by measurable performance rather than assumptions. Most teams define internal benchmarks across core metrics such as:
- Faithfulness
- Answer relevancy
- Context precision
- Context recall
These benchmarks help determine whether a system is ready for deployment.
For example:
- Low faithfulness: increased hallucination risk
- Low context recall: incomplete retrieval due to indexing or chunking issues
- Low context precision: retrieval configuration problems
Benchmarks allow teams to monitor improvements and make deployment decisions based on measurable performance.
Improving RAG Performance Based on Evaluation Metrics
Evaluation metrics not only identify issues but also guide targeted improvements.
| Issue | Recommended Solution |
| Low Faithfulness | Strengthen prompts to ensure responses use only the provided context and clearly indicate when information is unavailable |
| Low Context Recall | Optimize document chunking with smaller segments and controlled overlap |
| Low Context Precision | Review embedding models and retrieval configuration to reduce irrelevant results |
Conclusion: Building RAG Systems You Can Trust
Before deploying a RAG application, the real question is not “Does it work?” but “Can we prove it is reliable?”
A system that performs well in a demo may still generate hallucinated or unsupported answers in real-world scenarios. Proper evaluation focuses on four core signals: faithfulness, answer relevancy, context precision, and context recall. Together, these metrics determine whether a system is grounded in its sources, accurately addressing user queries, and retrieving the information it needs.
Enabling Reliable RAG Systems with ACL Digital
At ACL Digital, we believe that responsible AI deployment requires rigorous evaluation before systems reach users. Our approach focuses on building and validating RAG systems with measurable performance across key evaluation metrics, ensuring reliability, accuracy, and trust at scale.
From designing retrieval pipelines to implementing evaluation frameworks, we help organizations move beyond proof-of-concept and deploy production-ready AI systems with confidence.
If you’re looking to build reliable, production-ready RAG systems, our experts can help you establish a robust evaluation framework tailored to your needs. Contact us today.
Related Insights



Zero-Trust AI: Securing MCP-Based LLM Systems in Production
Siddharth Dange


Building Intelligent Agents on the Databricks Stack
Divyesh Patel